Abstract:
Recently there is a focus on driver monitoring systems in the automotive industry. The increasing number of traffic accidents due to fatigue and distraction became a problem of serious concern to society. According to the CDC motor vehicle safety division, one in five car accidents is caused by a distracted driver. Sadly, this translates to 425,000 people injured and 3,000 people killed by distracted driving every year. There are many approaches trying to effectively detect driver’s fatigue or distraction, but all of them suffer from either great complexity, leading to inability to be integrated in low computational power device, or oversimplicity, which leads to low accuracy of the final results of the method. Convolutional neural netowrks (CNNs) have a huge advantage over this problem as they offer robust models with complex features which are learnt instead of explicitly programmed.

Introduction:
This article’s aim is to propose real-time driver monitoring system with focus to distraction. The article presents state-of-the-art deep convolutional neural network achieving accuracy over 99.7% after being trained on 20K and validated on 2.5K over 10 classes. Starting with this 820K trainable parameters model we end up with 10 times smaller model with same accuracy, but with better speed and more compact.
Data:
The dataset used for training is provided by https://www.statefarm.com in order to help improve these alarming statistics mentioned above, and better insure their customers, by testing whether dashboard cameras can automatically detect drivers engaging in distracted behaviors.



The 10 classes to predict are:
- safe driving
- texting - right
- talking on the phone - right
- texting - left
- talking on the phone - left
- operating the radio
- drinking
- reachingg behind
- hair and makeup
- talking to passenger
In future I’m going to present bigger dataset with a few more classes, which I find important (eg. smoking, eating, etc.).
Solution
Three main approaches were investigated :
- Straight-forward deep CNN trained on ground truth values.
- Compressed CNN trained using dark knowledge.
- aSqueezeNet architecture.
After comparing the results from all of the approaches the article comes with the best model.
Straight-forward deep CNN trained on ground truth values
The first described approach is to build CNN and train it on the available dataset using Adam as optimizer and cathegorical crossentropy as loss function.
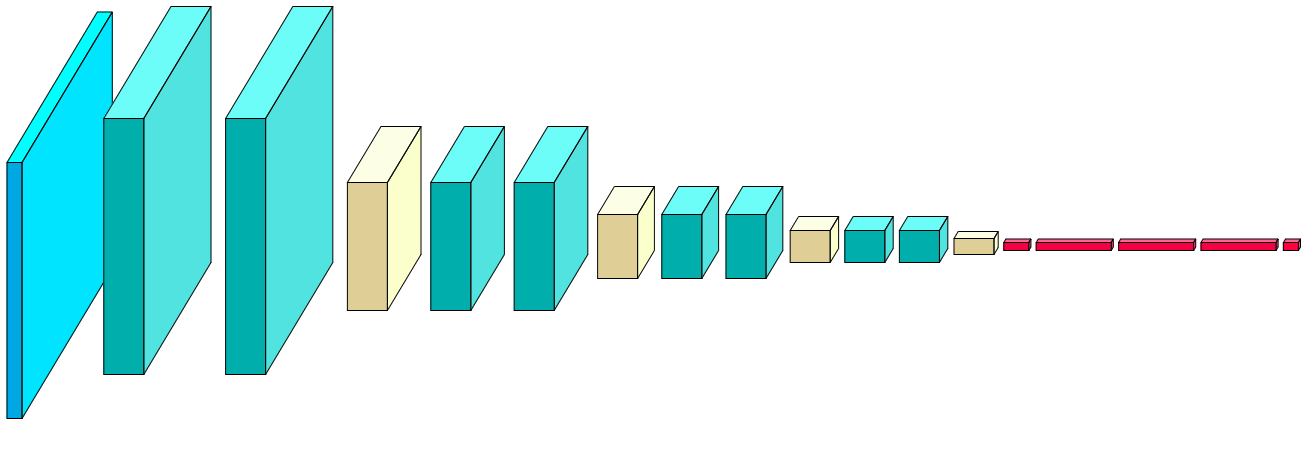 Fig1: aNet
Fig1: aNet
Here’s a summary of the model shown in Fig1:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 96, 128, 3) 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 96, 128, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 96, 128, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 48, 64, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 48, 64, 64) 36928
_________________________________________________________________
block2_conv2 (Conv2D) (None, 48, 64, 64) 36928
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 24, 32, 64) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 24, 32, 128) 73856
_________________________________________________________________
block3_conv2 (Conv2D) (None, 24, 32, 128) 147584
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 12, 16, 128) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 12, 16, 128) 147584
_________________________________________________________________
block4_conv2 (Conv2D) (None, 12, 16, 128) 147584
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 4, 5, 128) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 2560) 0
_________________________________________________________________
dense_1 (Dense) (None, 64) 163904
_________________________________________________________________
dense_2 (Dense) (None, 128) 8320
_________________________________________________________________
dense_3 (Dense) (None, 128) 16512
_________________________________________________________________
output (Dense) (None, 10) 1290
=================================================================
Total params: 819,210
Trainable params: 819,210
Non-trainable params: 0
After 30 epochs with batch size 32 the model achieves 0.9972 accuracy on the train set and 0.9938 accuracy on the validation set.
Compressed CNN trained using dark knowledge
Since the first approach is too computationally heavy we cannot achieve real-time prediction on embedded system, so we are going to use one really simple, but interesting idea proposed by Geoff Hinton.
The basic idea of the solution is to train a simpler model that mimics the CNN. To make it work, one replaces the actual class labels with predictions from the model we wish to mimic. This great idea can also be used to mimic complex ensemble models which results in even better compression as final result.
Really good brief explanation of the technique given from Rich Caruana:
We take a large, slow, but accurate model and compress it into a much smaller, faster, yet still accurate model. This allows us to separate the models used for learning from the models used to deliver the learned so that we can train large, complex models such as ensembles, but later make them small enough to fit on a PDA, hearing aid, or satellite. With model compression we can make models 1000 times smaller and faster with little or no loss in accuracy.
So we end up with predicted values from our first model, which we use to train this compressed CNN.
Reducing the compressed CNN parameters to 85K results in 0.9856 on train samples and 0.9737 accuracy on validation samples
Surprisingly if we use the same model, but instead we train it on ground truth values, we end up with almost the same results, which makes us go even further.
Training on ground truth values even smaller model with only 10K parameteres results in overfit and not so good model - 0.904 accuracy on training samples and 0.916 accuracy on validation samples.
Here dark knowledge comes in power and training a model with 10K which mimics our baseline model results in 0.948 accuracy on training data and 0.941 on validation data - much better results!
aSqueezeNet
Originally SqueezeNet provides an architecture achieving the same accuracy as AlexNet, but is 3x times faster and 500x smaller, compared to AlexNet.
The main ideas of SqueezeNet are:
- Using 1x1 (point-wise) filters to replace 3x3 filters, as the former only 1/9 of computation.
- Using 1x1 filters as a bottleneck layer to reduce depth so computation of the following 3x3 filters is reduced.
- Downsample late to keep a big feature
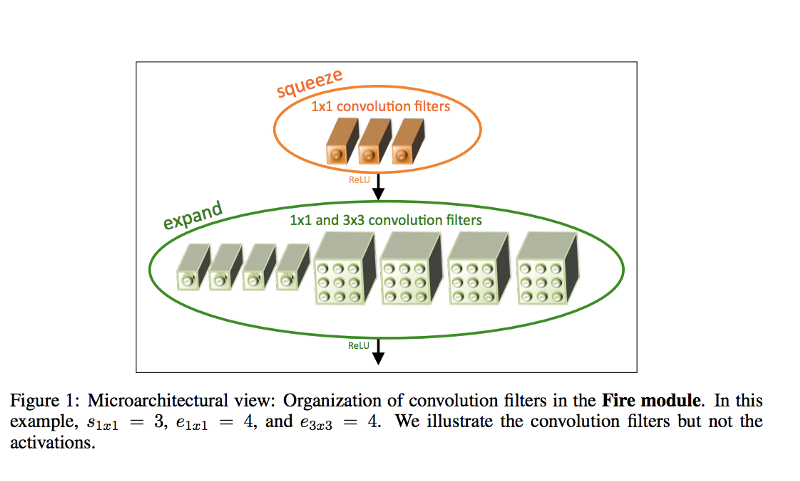
So comes the idea to use SqueezeNet-like architecture to achieve high accuracy and low computational requirement. That’s how aSqueezeNet comes. It’s architecture is the same as the original SqueezeNet, but it’s a bit smaller, so it achieves even better speed and size for the problem it solves.
Starting with 120K trainable parameters model we achieve 0.982 accuracy on train samples and 0.971 on validation samples.
Reducing it’s parameters to 75K we end up with 0.9823 accuracy on train and 0.9755 on validation and really fast and small model.
Comparison of the models for given number of parameters
| 10000 | 80000 | 820000 | ||||
|---|---|---|---|---|---|---|
| train | test | train | test | train | test | |
| aNet | 0.916 | 0.940 | 0.991 | 0.991 | 0.993 | 0.997 |
| aNet-DN | 0.941 | 0.948 | 0.973 | 0.985 | ||
| aSqueezeNet | 0.918 | 0.915 | 0.975 | 0.982 | ||
Please, note that though the numeric results as accuracy and coverage are equal for some models, there is difference in the models’ processing time and size!
Pretrained models can be found at the aNet github repo.
References:
[1] arXiv:1503.02531v1 [stat.ML] 9 Mar 2015
[2] arXiv:1602.07360v4 [cs.CV] 4 Nov 2016
[3] arXiv:1412.6980v9 [cs.LG] 30 Jan 2017